
EDA: NYC MTA Turnstile Data
NYC MTA Turnstile Data
Table of Contents
- Data Import
- Data Cleaning
- Analysis
- Which station has the most number of units?
- What is the total number of entries & exits across the subway system for February 1, 2013
- What station was the busiest on February 1, 2013? What turnstile was the busiest on that date?
- What stations have seen the most usage growth/decline in 2013?
- What dates are the least busy? Could you identify days on which stations were not operating at full capacity or closed entirely?
- What hour is the busiest for station CANAL ST in Q1 2013?
import pandas as pd
import os
import itertools
import time
import datetime
import matplotlib.pyplot as plt
def format_old_file(filename):
column_names = ['C/A', 'UNIT', 'SCP', 'DATE', 'TIME','DESC', 'ENTRIES', 'EXITS']
remainders = itertools.zip_longest(*[iter(range(3, 43))] * 5, fillvalue=0)
column_values = [[0, 1, 2, *row] for row in remainders]
frames = [pd.read_csv(filename, header=None, usecols=usecols,
names=column_names)
for usecols in column_values]
df = pd.concat(frames, axis=0)
df.reset_index(drop=True,inplace=True)
return df
Pull in 2013 Data
All txt files for the year of 2013 were downloaded from http://web.mta.info/developers/turnstile.html and placed in a local directory called ‘mta_data’. Data files created prior to 10/18/14 do not have one observation per row, and thus require some preprocessing and transformation (function above). Following this step, all the resulting dataframes from each weekly txt file are concatenated into one large dataframe containing all data for 2013. In all, it takes ~1 min to load in and process all the files (on my Mac at least).
Within the mta_data folder, a subdirectory called ‘2013’ contains all 2013 txt files. Additionally, within the mta_data directory there are two supporting data files:
- Most recent MTA data file for getting answer to question 1
- Remote-Booth-Station.xls to map stations to older data files
According to the MTA website, the data contains the following fields. Data prior to 10/18/14 contain a subset of the same fields. Fields not contained in older data is marked with an asterisk.
- C/A = Control Area (A002)
- UNIT = Remote Unit for a station (R051)
- SCP = Subunit Channel Position represents an specific address for a device (02-00-00)
- STATION* = Represents the station name the device is located at
- LINENAME* = Represents all train lines that can be boarded at this station Normally lines are represented by one character. LINENAME 456NQR repersents train server for 4, 5, 6, N, Q, and R trains.
- DIVISION* = Represents the Line originally the station belonged to BMT, IRT, or IND
- DATE = Represents the date (MM-DD-YY)
- TIME = Represents the time (hh:mm:ss) for a scheduled audit event
- DESc = Represent the “REGULAR” scheduled audit event (Normally occurs every 4 hours) 1. Audits may occur more that 4 hours due to planning, or troubleshooting activities. 2. Additionally, there may be a “RECOVR AUD” entry: This refers to a missed audit that was recovered.
- ENTRIES = The comulative entry register value for a device
- EXITS = The cumulative exit register value for a device
import os
data_dir = '../../mta_data/2013/'
filenames = [file for file in sorted(os.listdir(data_dir)) if 'turnstile' in file]
t = time.time()
df = pd.concat([format_old_file(data_dir + file) for file in filenames],axis=0)
print(f"Imported data in {time.time() -t} seconds")
print(f"Number of rows: {len(df)}")
Imported data in 46.12816309928894 seconds
Number of rows: 12380824
Pull in new data file
We also need to pull the latest data file which contains the stations that each unit is in, which is not included in 2013 data files. This data will be merged in to get the station to turnstile mapping.
Cleaning and Quality Check
Null Rows
na_rows = df.isna().any(axis=1).sum()
print(f"There are {na_rows} with na values ({round(na_rows/len(df) * 100,2)} %)")
There are 916414 with na values (7.4 %)
Most of the na values are likely an artifact of the initial parsing logic required for the older file format. Moreover, there is no effective or reasonable assumption that can made to fill in the missing values and, in fact, doing so incorrectly could make matters worse. With over 90% (10 million+) of the records intact, we will just drop the rows containing na values.
df.dropna(inplace=True)
Negative Entries/Exits
df.describe()
| ENTRIES | EXITS | |
|---|---|---|
| count | 1.146441e+07 | 1.146441e+07 |
| mean | 5.034486e+06 | 2.971423e+06 |
| std | 3.292653e+07 | 3.299601e+07 |
| min | -9.314769e+08 | -8.789686e+08 |
| 25% | 3.364450e+05 | 1.932042e+05 |
| 50% | 1.982436e+06 | 1.216322e+06 |
| 75% | 4.972726e+06 | 3.579545e+06 |
| max | 9.168487e+08 | 9.797130e+08 |
A quick description of the data shows that there appear to be negative values for the Entries and Exits. This doesn’t make any sense given that the columns are meant to be cumulative. However, while the exact reason these values are negative is unclear (may have something to do with DOOR OPEN/DOOR CLOSE events), from a quick check of some of the records the data still seems to be accurately counting the number of exits/entries in between each reading even if the value is abnormal. Thus, we can still calculate the change and then evaluate if we still get negative values there (which we’ll have to fix).
Dates
Combining the date and time columns into a separate datetime column will simplify analysis and reduce the number of columns. Additionally, as all analysis is being confined to 2013, we will ensure only dates in that year are represented.
df['DateTime'] = pd.to_datetime(df['DATE'] + ' ' + df['TIME'])
df = df.drop(columns=['DATE','TIME'])
df = df[(df.DateTime > '2013-01-01 00:00:00') & (df.DateTime < '2013-12-31 23:59:59')]
TurnStile and Entries/Exits change columns
We’ll create a turnstile column that is the combination of the C/A, UNIT, and SCP since that uniquely identifies a turnstile within a station and will simplify the groupby statements. Additionally, we’ll calculate the change in entries and exit at each reading for a turnstile, which will be needed for later analysis.
df = df.reset_index(drop=True)
df = df.assign(TurnStile=df['C/A'] + '-' + df['UNIT'] + '-' + df['SCP'])
df_sort = df.sort_values(['TurnStile','DateTime'])
df['EntriesChange'] = df_sort.groupby('TurnStile')['ENTRIES'].transform(pd.Series.diff)
df['ExitsChange'] = df_sort.groupby('TurnStile')['EXITS'].transform(pd.Series.diff)
# fill na values which mark the first measurement of the turnstile
df = df.fillna({'EntriesChange':0, 'ExitsChange':0})
Quality Check on Change columns
Doing a describe shows that there are some change values which are negative. This is doesnt make sense and we will have to amend the data.
df.describe()
| ENTRIES | EXITS | EntriesChange | ExitsChange | |
|---|---|---|---|---|
| count | 1.137625e+07 | 1.137625e+07 | 1.137625e+07 | 1.137625e+07 |
| mean | 5.043418e+06 | 2.975773e+06 | 8.206008e+02 | 6.460294e+02 |
| std | 3.300180e+07 | 3.307180e+07 | 9.819976e+05 | 1.025034e+06 |
| min | -9.314769e+08 | -8.789650e+08 | -9.314769e+08 | -9.797130e+08 |
| 25% | 3.366480e+05 | 1.932310e+05 | 1.000000e+00 | 1.000000e+00 |
| 50% | 1.982904e+06 | 1.216513e+06 | 5.200000e+01 | 3.700000e+01 |
| 75% | 4.973487e+06 | 3.579991e+06 | 2.100000e+02 | 1.450000e+02 |
| max | 9.168487e+08 | 9.797130e+08 | 9.168486e+08 | 9.719247e+08 |
tot_rows_neg = len(df.loc[(df['EntriesChange'] < 0) | (df['ExitsChange'] < 0)])
Total rows with negative change values: 2304
Percentage of negative change values rows out of total: 0.02%
These rows with negative values account for a whopping 0.02% of all the data. For such a small sample its not really worth it to do a deep dive and write a possibly complicated algorithm to figure out a reasonable value. We’ll just drop them.
However, with the negative values means we have the inverse happening where there are abnormally large numbers. For an example, see the slice below. These are not as easy to identify. We could use IQR or z-score to try to clearly identify them and delete, but we also risk losing data for stations that see actual jumps because of holidays or special events. We want to capture these as best we can so we’ll just set an upper limit of 10,000. If a row has more than 10,000 exits or entries in a 4 hour or less period, we’ll consider that too high. For 4 hours that’s a rate of ~41 people per minute for one turnstile.
df.loc[
(df.TurnStile == "R644-R135-01-00-00")
& (df.DateTime.dt.date.astype(str) == "2013-11-26")
].head()
| C/A | UNIT | SCP | DESC | ENTRIES | EXITS | DateTime | TurnStile | EntriesChange | ExitsChange | |
|---|---|---|---|---|---|---|---|---|---|---|
| 10334734 | R644 | R135 | 01-00-00 | REGULAR | 4039.0 | 1310543.0 | 2013-11-26 08:00:00 | R644-R135-01-00-00 | 0.0 | 65.0 |
| 10334735 | R644 | R135 | 01-00-00 | LGF-MAN | 334108.0 | 1440925.0 | 2013-11-26 12:25:04 | R644-R135-01-00-00 | 0.0 | 0.0 |
| 10363112 | R644 | R135 | 01-00-00 | RECOVR AUD | 334063.0 | 1440813.0 | 2013-11-26 08:00:00 | R644-R135-01-00-00 | 330024.0 | 130270.0 |
| 10363113 | R644 | R135 | 01-00-00 | LOGON | 334108.0 | 1440925.0 | 2013-11-26 12:25:15 | R644-R135-01-00-00 | 0.0 | 0.0 |
| 10389840 | R644 | R135 | 01-00-00 | REGULAR | 4040.0 | 1310668.0 | 2013-11-26 12:00:00 | R644-R135-01-00-00 | -330023.0 | -130145.0 |
# drop negative values
df = df[~((df['EntriesChange'] < 0) | (df['ExitsChange'] < 0))]
# drop records with values greater than 10,000
df = df[~((df['EntriesChange'] > 10000) | (df['ExitsChange'] > 10000))]
df.describe()
| ENTRIES | EXITS | EntriesChange | ExitsChange | |
|---|---|---|---|---|
| count | 1.137349e+07 | 1.137349e+07 | 1.137349e+07 | 1.137349e+07 |
| mean | 5.042996e+06 | 2.975560e+06 | 1.572528e+02 | 1.234072e+02 |
| std | 3.299406e+07 | 3.306292e+07 | 2.516331e+02 | 2.265497e+02 |
| min | -9.314769e+08 | -8.789650e+08 | 0.000000e+00 | 0.000000e+00 |
| 25% | 3.369660e+05 | 1.934675e+05 | 1.000000e+00 | 1.000000e+00 |
| 50% | 1.983519e+06 | 1.216895e+06 | 5.200000e+01 | 3.700000e+01 |
| 75% | 4.973984e+06 | 3.580515e+06 | 2.100000e+02 | 1.450000e+02 |
| max | 9.168487e+08 | 9.797130e+08 | 9.890000e+03 | 9.571000e+03 |
Much better. Now we’re ready
Question 1
Which station has the most number of units?
We can use the most recent data file to get the current number of units per stations. Also, 2013 data does not contain the station column.
new_df = pd.read_csv('../../mta_data/turnstile_210612.txt', engine='python')
new_df['TurnStile'] = new_df['C/A'] + '-' + new_df['UNIT'] + '-' + new_df['SCP']
fig, ax = plt.subplots(figsize=(25, 8))
largest_stations = (
new_df.drop_duplicates("TurnStile")
.groupby(["STATION"])
.size()
.sort_values(ascending=False)
.head(10)
)
largest_stations.plot(kind="bar", ax=ax)
ax.set(
title="Top 10 Largest Stations by Turnstile Count",
xlabel="Station",
ylabel="Number of TurnStiles",
)
ax.legend().set_visible(False)
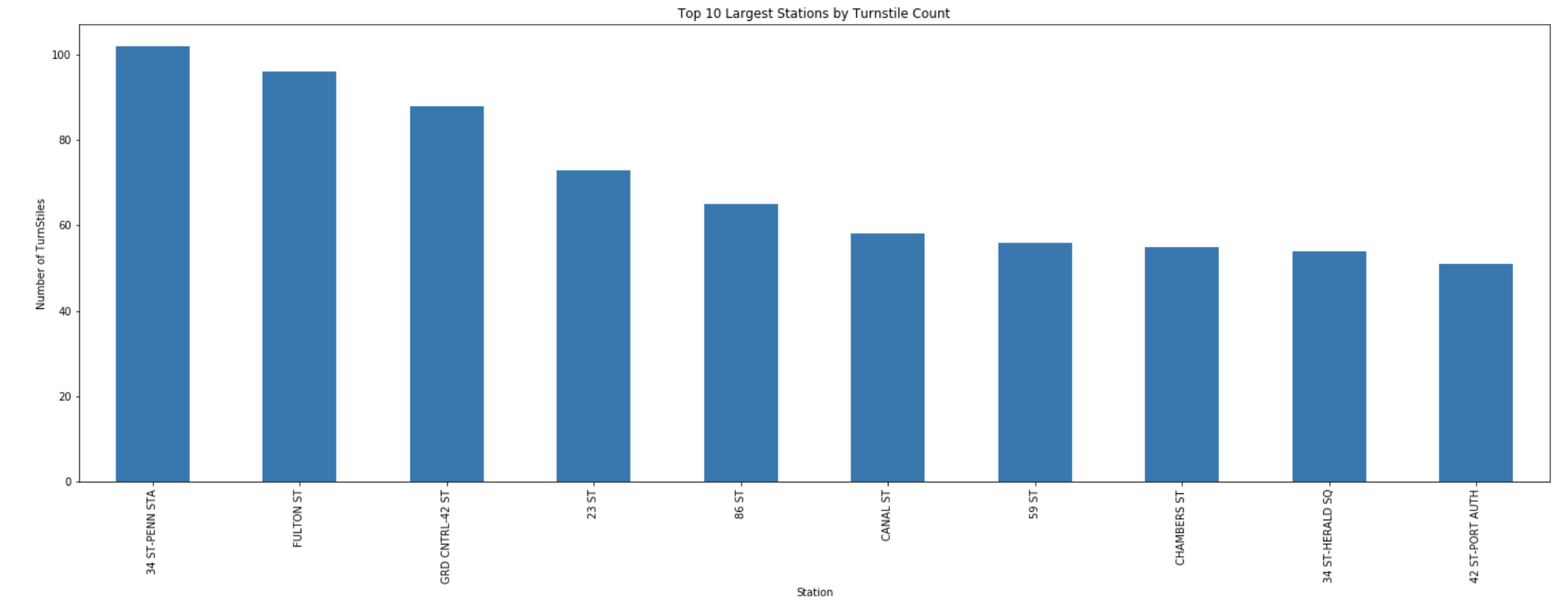
ANSWER
print(f"Answer: {pd.Series(largest_stations)[:1]}")
Answer: STATION
34 ST-PENN STA 102
dtype: int64
34 ST-PENN STATION has the most turnstiles with 102
Question 2
What is the total number of entries & exits across the subway system for February 1, 2013?
feb113_df = df.loc[df.DateTime.dt.date.astype(str) == '2013-02-01']
feb113_df.head()
| C/A | UNIT | SCP | DESC | ENTRIES | EXITS | DateTime | TurnStile | EntriesChange | ExitsChange | |
|---|---|---|---|---|---|---|---|---|---|---|
| 753397 | A002 | R051 | 02-00-00 | REGULAR | 3974913.0 | 1370326.0 | 2013-02-01 15:00:00 | A002-R051-02-00-00 | 207.0 | 32.0 |
| 753403 | A002 | R051 | 02-00-01 | REGULAR | 3792617.0 | 821317.0 | 2013-02-01 15:00:00 | A002-R051-02-00-01 | 166.0 | 25.0 |
| 753418 | A002 | R051 | 02-03-01 | REGULAR | 3612280.0 | 5634445.0 | 2013-02-01 19:00:00 | A002-R051-02-03-01 | 621.0 | 377.0 |
| 753454 | A002 | R051 | 02-03-06 | REGULAR | 4959945.0 | 439721.0 | 2013-02-01 07:00:00 | A002-R051-02-03-06 | 46.0 | 4.0 |
| 753460 | A002 | R051 | 02-05-00 | REGULAR | 907.0 | 0.0 | 2013-02-01 15:00:00 | A002-R051-02-05-00 | 0.0 | 0.0 |
ANSWER
tot_entries = feb113_df.EntriesChange.sum()
tot_exits = feb113_df.ExitsChange.sum()
Total number of entries across the whole subway system on February 1, 2013: 5818588.0
Total number of exits across the whole subway system on February 1, 2013: 4516096.0
On February 1st 2013, 5.81 million people entered the subway and only 4.51 million came out. Terrifying. Although that makes sense because a lot of people will actually use the emergency exits on their way out, which wouldn’t get counted. That’s about 20%. Interesting
Question 3
What station was the busiest on February 1, 2013? What turnstile was the busiest on that date?
To answer this we first have to map the stations to their turnstiles since Feb 2013 data does not contain the station field. MTA provides a Remote-Booth-Station.xls file to help with this. I downloaded it into my home directory and read it in to merge with the Feb 2013 data.
Note: Some booths and/or units do not have records in the excel file. Possibly they were removed in the years gone by.
stat_map = pd.read_excel('../../mta_data/Remote-Booth-Station.xls')
feb113_df = feb113_df.merge(
stat_map, left_on=["C/A", "UNIT"], right_on=["Booth", "Remote"], how="left"
)
print(
f"{feb113_df.isna().any(axis=1).sum()} turnstile do not have mapped stations available "
+ f"({feb113_df.isna().any(axis=1).sum()/len(feb113_df)*100}%)"
)
558 turnstile do not have mapped stations available (1.8250204415372036%)
ANSWER
busiest_stations = pd.DataFrame((feb113_df.groupby('Station')['EntriesChange'].sum() +
feb113_df.groupby('Station')['ExitsChange'].sum()
), columns=['Entries+Exits']
).sort_values(by="Entries+Exits",ascending=False).head()
busiest_stations
| Entries+Exits | |
|---|---|
| Station | |
| 34 ST-PENN STA | 348286.0 |
| 42 ST-GRD CNTRL | 327422.0 |
| 34 ST-HERALD SQ | 222322.0 |
| 86 ST | 208671.0 |
| 14 ST-UNION SQ | 208269.0 |
Busiest Station: 34 ST-PENN STA
Total Entries + Exits on Feb 1st 2013: 348286
busiest_turnstiles = pd.DataFrame(
(feb113_df.groupby('TurnStile')['EntriesChange'].sum() +
feb113_df.groupby('TurnStile')['ExitsChange'].sum()
), columns=['Entries+Exits']).sort_values(by="Entries+Exits",ascending=False).head()
busiest_turnstiles
| Entries+Exits | |
|---|---|
| TurnStile | |
| R240-R047-00-00-00 | 13529.0 |
| N601-R319-00-00-00 | 13066.0 |
| N063A-R011-00-00-00 | 12188.0 |
| R221-R170-01-00-00 | 12060.0 |
| R249-R179-01-00-09 | 11692.0 |
# station that the busiest turnstile is located in
tstile_station = feb113_df.loc[
feb113_df.TurnStile == busiest_turnstiles.iloc[0].name
]["Station"].iloc[0]
Busiest Turnstile: R240-R047-00-00-00
Located in Station: 42 ST-GRD CNTRL
Total Entries + Exits on Feb 1st 2013: 13529
Question 4
What stations have seen the most usage growth/decline in 2013?
To avoid the risk of periodicity or anomalies on certain dates by check the percent change from the first to last date, we can take the average quarterly business for each station and then compare the Q1 to Q4 traffic to see how its changed.
# merge in station mapping to get the station for each turnstile
df = df.merge(stat_map, left_on=["C/A","UNIT"],right_on=["Booth","Remote"],how='left')
df['Entries+Exits'] = df['EntriesChange'] + df['ExitsChange']
# calculate Q1 and Q4 mean traffic for each station
q1 = (
df.loc[df["DateTime"].dt.month.isin([1, 2, 3])]
.groupby(["Station"])["Entries+Exits"]
.mean()
.to_frame("Q1Mean")
)
q4 = (
df.loc[df["DateTime"].dt.month.isin([10, 11, 12])]
.groupby(["Station"])["Entries+Exits"]
.mean()
.to_frame("Q4Mean")
)
q_df = q1.join(q4)
q_df["PercentChange"] = round(
((q_df["Q4Mean"] - q_df["Q1Mean"]) / q_df["Q1Mean"]) * 100, 3
)
Stations with largest growth in 2013
q_df.sort_values('PercentChange', ascending=False).head(3)
| Q1Mean | Q4Mean | PercentChange | |
|---|---|---|---|
| Station | |||
| BEACH 90 ST | 0.050420 | 43.670715 | 86513.585 |
| AQUEDUCT TRACK | 0.370667 | 42.954366 | 11488.408 |
| BEACH 44 ST | 1.610232 | 29.146561 | 1710.084 |
aqueduct_df = df.loc[df.Station == 'AQUEDUCT TRACK'].groupby(df['DateTime'].dt.month).agg({'Entries+Exits':'mean'}).rename(columns={"Entries+Exits":"Aqueduct Track"})
beach44_df = df.loc[df.Station == 'BEACH 44 ST'].groupby(df['DateTime'].dt.month).agg({'Entries+Exits':'mean'}).rename(columns={"Entries+Exits":"Beach 44 ST"})
beach90_df = df.loc[df.Station == 'BEACH 90 ST'].groupby(df['DateTime'].dt.month).agg({'Entries+Exits':'mean'}).rename(columns={"Entries+Exits":"Beach 90 ST"})
beach44_df.join(beach90_df).join(aqueduct_df).fillna(0).plot(kind='line')
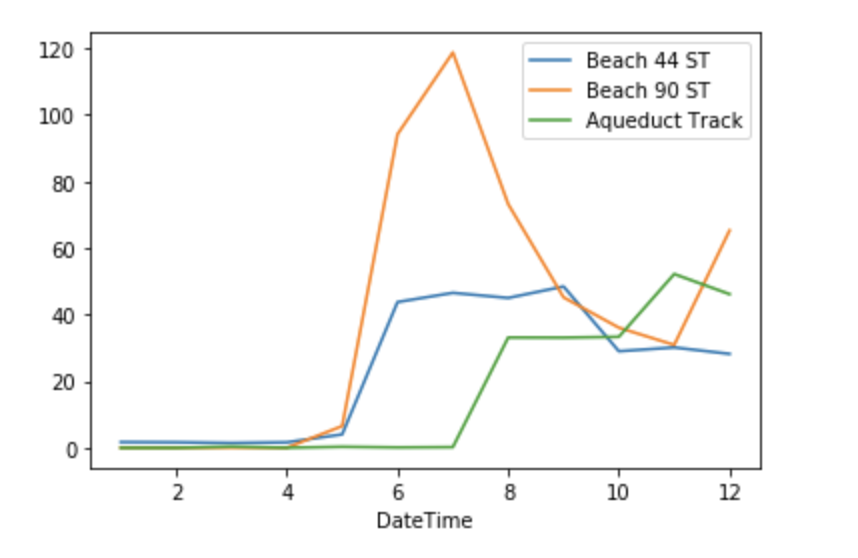
Stations with largest decline in 2013
q_df.sort_values('PercentChange').head(3)
| Q1Mean | Q4Mean | PercentChange | |
|---|---|---|---|
| Station | |||
| HOWARD BCH-JFK | 118.424049 | 49.343952 | -58.333 |
| WHITEHALL ST | 217.121889 | 90.847422 | -58.158 |
| DYCKMAN ST | 511.564791 | 230.912285 | -54.862 |
howard_df = df.loc[df.Station == 'HOWARD BCH-JFK'].groupby(df['DateTime'].dt.month).agg({'Entries+Exits':'mean'}).rename(columns={"Entries+Exits":"Howard Beach JFK"})
whitehall_df = df.loc[df.Station == 'WHITEHALL ST'].groupby(df['DateTime'].dt.month).agg({'Entries+Exits':'mean'}).rename(columns={"Entries+Exits":"Whitehall St"})
dyckman_df = df.loc[df.Station == 'DYCKMAN ST'].groupby(df['DateTime'].dt.month).agg({'Entries+Exits':'mean'}).rename(columns={"Entries+Exits":"Dyckman St"})
howard_df.join(whitehall_df).join(dyckman_df).fillna(0).plot(kind='line')
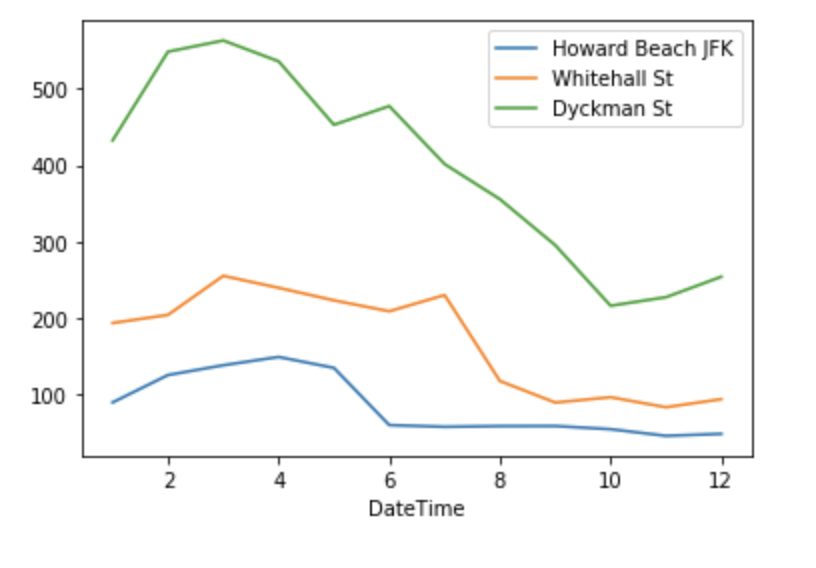
ANSWER
Stations with largest growth
- Beach 90 St: +86,513%
- Aqueduct Track: +11,488%
- Beach 44 St: +1710%
Fun Fact: A quick google search shows that the Beach St stations were actually entirely or partially closed due to damage from Hurricane Sandy. They opened back up in May 2013, which corresponds to the sharp increase in overall traffic in month 5. Alternatively, Aqueduct track was close from 2011-2013 to rebuild it for better access to the Resorts World Casino, opening back up in August 2013.
Stations with largest decline
- Howard Beach JFK: -58.3%
- Whitehall St: -58.1%
- Dyckman St: -54.8%
Fun Fact: Again, Hurricane Sandy comes into play. Because of numerous closings of other subway stations that were damaged by the hurricane, Howard Beach JFK served as the alternative route while these stations were rebuilt. As a result, Howard Beach JFK had very high ridership numbers early in the year, but as the closed stations re-opened the traffic fell back to normal levels. On the other hand, Whitehall St and Dyckman St experienced decline in traffic because they went under rehabilitation work in the later part of 2013.
Question 5
What dates are the least busy? Could you identify days on which stations were not operating at full capacity or closed entirely?
Least Busy Days
df['DATE'] = df['DateTime'].dt.date
least_busy_days = pd.DataFrame(df.groupby('DATE')['Entries+Exits'].sum().sort_values().head(3)).reset_index()
least_busy_days['DOW'] = pd.to_datetime(least_busy_days['DATE']).dt.day_name()
least_busy_days
| DATE | Entries+Exits | DOW | |
|---|---|---|---|
| 0 | 2013-12-25 | 3452962.0 | Wednesday |
| 1 | 2013-01-01 | 3557056.0 | Tuesday |
| 2 | 2013-11-28 | 4281943.0 | Thursday |
Not too surprising that the least traveled days happen to be the biggest holidays of the year with Christmas, New Years, and Thanksgiving taking the first, second, and third place, respectively.
Closed Stations
Closed stations would have no entries or exits at any turnstile for the day.
In other words: Completely Closed = total ridership for the day is zero
closed_stations = (
df.groupby(["Station", "DATE"])["Entries+Exits"]
.sum()
.to_frame("DailyTraffic")
.query("DailyTraffic == 0")
)
closed_stations = (
closed_stations.reset_index().groupby("DATE").agg(lambda x: x.tolist())
)
closed_stations["NumberOfStationsClosed"] = closed_stations["Station"].apply(
lambda x: len(x)
)
Number of days which have a station closed: 152
Number of stations closed for the day throughout 2013: 213
closed_stations.sort_values('NumberOfStationsClosed', ascending=False).drop(columns=['DailyTraffic']).head()
| Station | NumberOfStationsClosed | |
|---|---|---|
| DATE | ||
| 2013-05-18 | [BEACH 105 ST, BEACH 90 ST, BEACH 98 ST, ORCHA... | 5 |
| 2013-05-19 | [BEACH 105 ST, BEACH 44 ST, BEACH 98 ST, ORCHA... | 4 |
| 2013-04-07 | [190 ST, AQUEDUCT TRACK, CRESCENT ST, FOREST P... | 4 |
| 2013-03-31 | [AQUEDUCT TRACK, BEACH 90 ST, CLEVELAND ST, CR... | 4 |
| 2013-01-06 | [14TH STREET, 9TH STREET, KINGSTON AVE, TWENTY... | 4 |
5 stations were closed on May 18th which was the highest amount for the year
Partial Capacity
Stations not operating at full capacity would have no entries or exits for only a portion of the turnstiles for the day.
Partial = some turnstile are zero
closed_turnstiles = df.groupby(['Station','TurnStile','DATE'])['Entries+Exits'].sum().to_frame('DailyTSTraffic').query("DailyTSTraffic == 0")
num_closed_ts = closed_turnstiles.reset_index().groupby(['Station','DATE']).count().drop(columns=["TurnStile"]).rename(columns={'DailyTSTraffic':'NumberClosed'})
partial_operating = df[['Station','TurnStile','DateTime','DATE']].merge(num_closed_ts.reset_index(), on=['Station','DATE'], how='left')
partial_operating = partial_operating.query("NumberClosed > 0")
station_turnstiles = partial_operating.drop_duplicates(subset=['TurnStile','DATE']).groupby(['Station','DATE']).size().to_frame('TotalTurnStiles')
partial_operating = partial_operating.merge(station_turnstiles, on=['Station','DATE'], how='left')[['Station','DATE','NumberClosed','TotalTurnStiles']]
partial_operating['OperatingCapacity'] = round(100*(
(partial_operating['TotalTurnStiles'] - partial_operating['NumberClosed'])/partial_operating['TotalTurnStiles']),2)
partial_operating = partial_operating.drop_duplicates(subset=['Station','DATE']).reset_index().groupby('DATE').agg(lambda x: x.tolist())
partial_operating['NumberOfPartialOperatingStations'] = partial_operating['Station'].apply(lambda x: len(x))
partial_operating[['Station','OperatingCapacity','NumberOfPartialOperatingStations']].sort_values('NumberOfPartialOperatingStations',ascending=False).head()
| Station | OperatingCapacity | NumberOfPartialOperatingStations | |
|---|---|---|---|
| DATE | |||
| 2013-08-18 | [LEXINGTON AVE, 5 AVE-59 ST, 49 ST-7 AVE, 34 S... | [80.0, 85.71, 90.91, 96.3, 94.74, 85.71, 44.44... | 171 |
| 2013-11-17 | [LEXINGTON AVE, 5 AVE-59 ST, 49 ST-7 AVE, 34 S... | [80.0, 92.86, 90.91, 96.3, 97.37, 82.14, 33.33... | 170 |
| 2013-10-20 | [LEXINGTON AVE, 5 AVE-59 ST, 49 ST-7 AVE, 42 S... | [80.0, 85.71, 95.45, 96.0, 98.15, 97.37, 87.5,... | 168 |
| 2013-10-06 | [LEXINGTON AVE, 5 AVE-59 ST, 49 ST-7 AVE, 42 S... | [90.0, 92.86, 90.91, 96.0, 98.15, 83.93, 66.67... | 166 |
| 2013-11-03 | [LEXINGTON AVE, 5 AVE-59 ST, 49 ST-7 AVE, 34 S... | [80.0, 92.86, 90.91, 98.15, 87.5, 66.67, 17.65... | 161 |
ANSWER
Least Busy Dates
Not too surprising that the biggest holidays are the least busy days
- Christmas (2013-12-25)
- New Years (2013-01-01)
- Thanksgiving (2013-11-28)
Completely closed and partially closed stations
Refer to the above data frames to see the list of stations that are either completely or partially closed on certain dates.
Bonus
What hour is the busiest for station CANAL ST in Q1 2013?
# filter data down to CANAL ST in Q1
canalq12013 = df.loc[(df['Station'] == 'CANAL ST') & (df['DateTime'].dt.month.isin([1,2,3]))]
# resample data to get hourly frequency, using linear interpolation to fill in hour numbers
canalq12013 = canalq12013.groupby(['TurnStile']).resample('60T', on='DateTime').mean().reset_index()
canalq12013['Hour'] = canalq12013['DateTime'].dt.hour
canalq12013.interpolate(method='linear').reset_index().groupby('Hour').mean().sort_values('Entries+Exits', ascending=False)['Entries+Exits'].head()
Hour
20 627.749974
19 626.143669
18 588.330532
17 551.228967
21 540.642590
Name: Entries+Exits, dtype: float64
ANSWER
The busiest hour for CANAL ST in Q1 2013 is hour 20 (8pm), followed closely by hour 19 and 18. So, it looks like 5-9pm sees the highest traffic. Makes sense for rush hour